Measuring Efficiency of SOC Neural Network Chips: A Comprehensive Approach
As artificial intelligence continues to revolutionize various industries, the demand for efficient System-on-Chip (SOC) neural network processors has skyrocketed. When designing the 56 AI One camera, selecting the System on Chip (SoC) based on both performance and cost was crucial. Over the last 4 years I got the opportunity to work and evaluate difference SoCs , ranging from Nvidia Jetson to Ambarella CV25. These SoC are designed to accelerate AI workloads, but how do we measure their efficiency? This blog post explores the key metrics and methodologies used to evaluate the performance of SOC neural network chips.

Nvidia Jetson Nano , Jetson Xavier modules
Benchmarking Methodologies
Standard industry benchmarks like MLPerf provide a common ground for comparing different chips across a range of AI tasks, including image classification, object detection, and natural language processing. The MLPerf benchmarks measure consistent performance metrics such as training time to target quality, inference latency, and throughput. This ensures that the performance comparisons are based on well-defined and universally accepted criteria. These benchmarks typically measure both inference and training performance, offering insights into how chips perform in various scenarios. However, standard benchmarks alone may not tell the whole story.
Lessons Learned: Why TOPs Number Isn’t Enough
TOPS (Tera Operations Per Second) has long been a go-to metric for comparing AI chip performance, but it’s increasingly clear that this measure alone falls short in capturing real-world AI chip efficiency. While TOPS provides a quick snapshot of raw computational power, it fails to account for critical factors like memory bandwidth, data movement costs, and the varying computational demands of different AI models. For instance, a chip boasting high TOPS might underperform in practice due to memory bottlenecks or inefficient handling of sparse operations common in many neural networks. Through my experience working with and evaluating various SoCs, from Nvidia Jetson Nano to Ambarella CV25, I’ve gathered significant insights in this domain.
Custom benchmarks tailored to specific use cases are equally important, as they can reveal how a chip performs under real-world conditions relevant to its intended application. For instance, an edge AI chip for autonomous vehicles might be benchmarked using specific computer vision tasks under varying lighting and weather conditions. It’s crucial to employ a diverse set of workloads in testing, encompassing different neural network architectures (CNNs, RNNs, Transformers), model sizes, and precision levels (FP32, FP16, INT8). This diversity ensures a comprehensive evaluation of the chip’s versatility and efficiency across various AI applications. Additionally, benchmarking should consider not just raw performance, but also power consumption, thermal characteristics, and consistency of performance over extended periods. By combining standardized benchmarks with application-specific tests and a wide range of workloads, we can gain a holistic understanding of a SOC Neural Network Chip’s efficiency and suitability for different AI tasks.
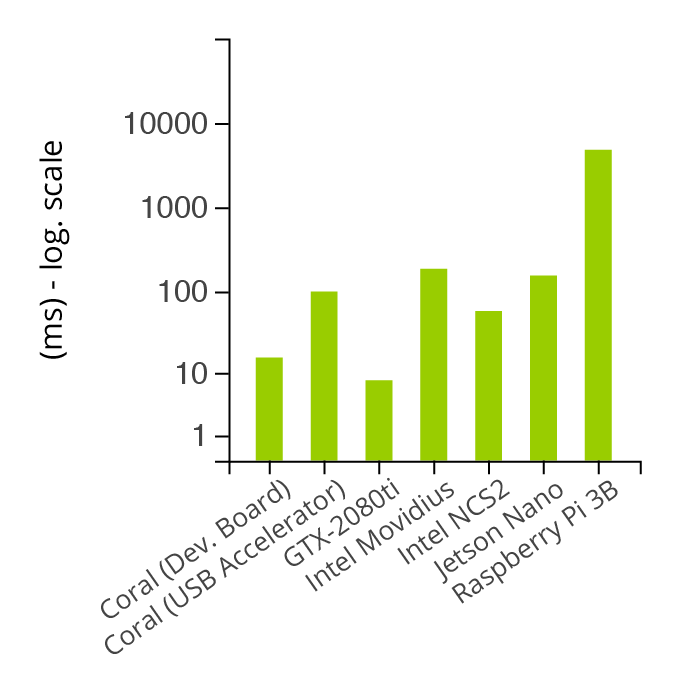
Average inference time by device
TOPS : Tera Operations Per Second
The most common metric used in the industry is TOPS (Tera Operations Per Second), which measures the raw computational power of a chip. TOPS indicates how many trillion operations the chip can perform in one second, providing a straightforward comparison of processing capabilities.
However, TOPS alone doesn’t paint the full picture of a chip’s efficiency. That’s where TOPS/W (TOPS per Watt) comes in. This metric combines processing power with energy consumption, offering insight into the chip’s efficiency. A higher TOPS/W indicates better performance per unit of power, which is crucial for mobile and edge devices with limited energy resources. It is important to calculate the TOPS of the SoC and obtain precise measurements once the AI pipelines are deployed.
Calculating TOPS for a Deep Learning Computer Vision Model:
Understand the model architecture: First, you need to know the structure of your model, including the number and types of layers, the size of input tensors, and the number of parameters in each layer.
Count the operations: For each layer in your model, count the number of floating-point operations (FLOPs) required for a single forward pass.
The main operations to consider are:
Convolutions
Matrix multiplications
Activations
Pooling operations
Calculate FLOPs for convolutional layers: For a convolutional layer: FLOPs = 2 H W Cin Cout K K Where:
H and W are the height and width of the output feature map
Cin is the number of input channels
Cout is the number of output channels
K is the kernel size
For a fully connected layer: FLOPs = 2 Nin Nout Where:
Nin is the number of input neurons
Nout is the number of output neurons
Sum up the total FLOPs: Add up the FLOPs from all layers to get the total number of operations for one forward pass of the model.
Consider the inference speed: Determine how many inferences your hardware can perform per second. This is often provided by the hardware manufacturer or can be measured through benchmarking.
Calculate TOPS: TOPS = (Total FLOPs * Inferences per second) / 10¹² This gives you the Tera Operations Per Second.
Example: Let’s say you have a simple CNN with:
1 convolutional layer: 3x3 kernel, 3 input channels, 64 output channels, 224x224 input size
1 fully connected layer: 50,176 inputs, 1000 outputs
The hardware can perform 100 inferences per second
Calculations:
Conv layer FLOPs = 2 224 224 3 64 3 3 = 173,408,256
FC layer FLOPs = 2 50,176 1000 = 100,352,000
Total FLOPs = 173,408,256 + 100,352,000 = 273,760,256
TOPS = (273,760,256 * 100) / 10¹² = 0.0274 TOPS
This method provides a rough estimate of TOPS. In practice, the calculation can be more complex due to factors like optimizations, quantization, and the specific hardware architecture being used.
Note: The TOPS calculation assumes 100 inferences per second. If this assumption is incorrect or needs to be adjusted, the final TOPS value would change accordingly.
Frames per Second (FPS)
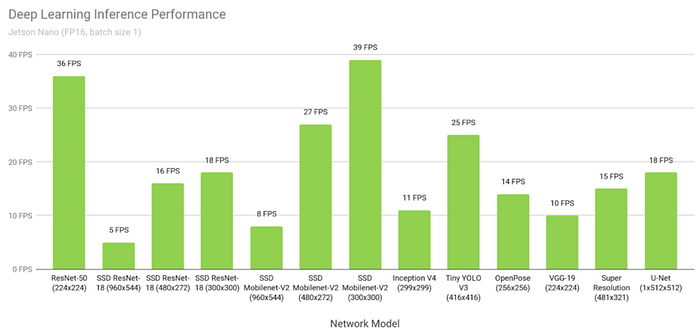
While TOPS and TOPS/W are important, they don’t always translate directly to real-world performance. This is where application-specific metrics come into play. For vision-related tasks, Frames per Second (FPS) measures how many image frames a chip can process in real-time, which is particularly relevant for applications like video analytics or autonomous driving. Latency, on the other hand, measures the time taken to complete a single inference, which is critical for real-time applications that require quick responses.
Memory Bandwidth

56 AI One Camera powered by Ambarella CV25
Another crucial aspect of neural network chip efficiency is memory performance. Memory bandwidth can often become a bottleneck in neural network processing, limiting the chip’s ability to fully utilize its computational resources. High memory bandwidth generally allows for better utilization of the chip’s processing power. Additionally, for applications where space is at a premium, area efficiency (measured in TOPS/mm²) becomes an important consideration, relating performance to chip size.
It’s also important to consider the chip’s flexibility and support for different neural network architectures. While not directly related to chip performance, the accuracy achieved on standard benchmarks helps evaluate how well the chip supports various neural network models. Some chips may excel at certain types of networks but perform poorly on others, so it’s crucial to evaluate performance across a range of relevant models and tasks.
Conclusion
Lastly, for commercial applications, the cost-effectiveness of a chip is a critical factor. Performance per dollar helps compare different solutions in terms of their economic viability. When evaluating SOC neural network chips, it’s essential to consider multiple metrics and how they relate to your specific use case. A chip with high TOPS might not be the best choice if power consumption is a primary concern, while a highly energy-efficient chip might fall short in applications requiring high-speed processing. By taking a comprehensive approach and considering various metrics, developers and businesses can make informed decisions when selecting the most suitable SOC neural network chip for their needs.

